通过生成式预训练提高语言模型的理解能力。
摘要
「自然语言理解」包括了文本蕴涵、问答、语义相似性评估和文档分类等多种不同的任务。尽管大型无标注文本语料库是很丰富的,但用于学习这些特定任务的标注数据却比较稀缺,这使得以判别方式训练的模型难以表现良好。我们证明,在多样化的无标注文本语料库上对语言模型进行「生成式预训练」(即 GPT),然后对每个特定任务进行「判别式微调」,可以在这些任务上实现大幅能力提升。与以前的方法不同,我们在微调过程中使用任务感知输入变换,在不需要对模型架构进行大量更改的情况下实现有效的迁移。我们在一系列自然语言理解基准任务上展示了我们方法的有效性。我们的通用任务不可知模型优于使用专门为每个任务定制的架构的判别式训练模型,在 12 个研究任务中有 9 个任务上显著改善了最先进水平。例如,我们在常识推理(Stories Cloze Test)上实现了 8.9% 的绝对提升,在问答(RACE)上实现了 5.7% 的提升,在文本蕴涵(MultiNLI)上实现了 1.5% 的提升。
1. 导言
学会有效地从原始文本中学习对于减轻自然语言处理(NLP)中对监督学习的依赖至关重要。大多数深度学习方法需要大量手动标注的数据,这限制了它们在许多缺乏注释资源的领域中的适用性[61]。在这些情况下,能够利用未标注数据中的语言信息的模型提供了一种收集更多注释的有价值的替代方案,而收集这些注释可能是耗时且昂贵的。此外,即使在监督较多(considerable supervision)的情况下,以无监督的方式学习良好的表示(good representations)也可以带来显著的性能提升。迄今为止最引人注目的证据是广泛使用预训练词嵌入[10, 39, 42]来提高一系列 NLP 任务性能[8, 11, 26, 45]。
然而,从未标注文本中提取比词级信息(word-level information)更多的信息具有挑战性。原因有两个:首先,不清楚哪种类型的优化目标(optimization objectives)在学习对于迁移有用的文本表示1(text representations)方面最有效。近期研究已经考察了各种目标,如语言建模[44]、机器翻译[38]和话语连贯性[22],在不同任务上,每种方法的表现也不同(在 A 任务上方法 1 优于方法 2;在 B 任务上可能相反)。其次,关于如何最有效地将这些学到的表示迁移到目标任务上,尚无共识。现有技术涉及对模型架构进行针对特定任务的更改[43, 44]、使用复杂的学习方案[21]以及添加辅助学习目标[50]。这些不确定性使得开发用于语言处理的有效半监督学习方法变得困难。
在本文中,我们探讨了一种使用无监督预训练和监督微调相结合的半监督方法来进行语言理解任务。我们的目标是学习一种通用表示,可以在很少的调整下适应各种任务。我们假设有大量未标记文本的语料库和几个带有手动注释训练示例的数据集(目标任务)。我们的设置不要求这些目标任务与未标记语料库在同一领域。我们采用两阶段训练过程。首先,我们在未标记数据上使用语言建模目标来学习神经网络模型的初始参数。随后,我们使用相应的监督目标将这些参数调整以适应目标任务。
对于我们的模型架构,我们采用了 Transformer 模型[62],它已被证明在各种任务上表现出色,如机器翻译[62]、文档生成[34]和句法解析[29]。与循环网络等替代方案相比,选择的这种模型为我们提供了一个更加结构化的记忆,用于处理文本中的长距离依赖关系,从而在各种不同任务中实现了稳健的迁移性能。在迁移过程中,我们利用遍历式方法[52],针对特定任务对输入进行调整,该方法将结构化文本输入作为一个连续的 token 序列进行处理。正如我们在实验中所展示的,这些调整使我们能够在对预训练模型的架构进行最小改动的情况下进行有效的微调2。
我们在四种类型的语言理解任务上评估我们的方法,包括自然语言推理、问题回答、语义相似性和文本分类。我们的通用任务无关模型胜过了采用针对每个任务专门设计的架构的判别式训练模型3,在研究的 12 个任务中有 9 个任务显著提高了技术水平。例如,我们在常识推理(Stories Cloze Test)[40]上实现了 8.9% 的绝对改进,在问题回答(RACE)[30]上实现了 5.7% 的改进,在文本蕴含(MultiNLI)[66]上实现了 1.5% 的改进,以及在最近引入的 GLUE 多任务基准[64]上实现了 5.5% 的改进。我们还分析了预训练模型在四种不同设置下的零样本行为,并证明它获取了对下游任务有用的语言知识。
2. 相关工作
NLP 的半监督学习:我们的工作大致属于自然语言半监督学习的范畴。这一范式引起了广泛关注,应用于诸如序列标记[24, 33, 57]或文本分类[41, 70]等任务。最早的方法使用未标注数据计算单词级或短语级统计信息,然后将其用作监督模型中的特征[33]。在过去的几年里,研究人员已经证明了使用词嵌入[11, 39, 42]的好处,这些词嵌入在未标注的语料库上进行训练,以提高各种任务的性能[8, 11, 26, 45]。然而,这些方法主要迁移单词级信息,而我们的目标是捕捉更高级别的语义。
最近的方法研究了从未标注数据中学习和利用超过单词级语义的方法。可以使用未标注语料库训练的短语级或句子级嵌入已被用于将文本编码为适合各种目标任务的向量表示[28, 32, 1, 36, 22, 12, 56, 31]。
无监督预训练:无监督预训练是半监督学习的一个特例,其目标是寻找一个好的初始化点,而不是修改监督学习目标。早期的工作探讨了这种技术在图像分类[20, 49, 63]和回归任务[3]中的应用。随后的研究[15]表明,预训练作为一种正则化方案,能够在深度神经网络中实现更好的泛化。在最近的工作中,该方法已经被用于帮助训练各种任务的深度神经网络,如图像分类[69]、语音识别[68]、实体消歧[17]和机器翻译[48]。
与我们的工作最接近的一条研究路线是使用语言建模目标预训练神经网络,然后在有监督的目标任务上对其进行微调。Dai 等人[13]和 Howard 和 Ruder[21]遵循这种方法来改进文本分类。然而,尽管预训练阶段有助于捕捉一些语言信息,但他们使用 LSTM 模型,这一模型将其预测能力限制在一个比较小的范围内。相反,我们选择的 transformer 网络允许我们捕捉更长的语言结构,如我们的实验中所示。此外,我们还展示了我们的模型在更广泛的任务范围内的有效性,包括自然语言推理、释义检测和故事补全。其他方法[43, 44, 38]在训练目标任务的监督模型时,使用预训练语言或机器翻译模型的隐藏表示(hidden representations)作为辅助特征。这涉及到为每个独立的目标任务引入大量新的参数,而在迁移过程中,我们对模型架构的改变最小。
辅助训练目标:添加辅助无监督训练目标是半监督学习的另一种形式。Collobert 和 Weston[10]的早期工作使用了各种辅助 NLP 任务,如词性标注、分块、命名实体识别和语言建模来改进语义角色标注。最近,Rei[50]在他们的目标任务目标中添加了辅助语言建模目标,并在序列标注任务上获得了性能提升。我们的实验也使用辅助目标,但如我们所示,无监督预训练已经学会了与目标任务相关的多种语言方面。
3. 框架
我们的训练过程包含 2 个阶段。第一阶段是在大型文本语料上学习高容量的语言模型。接下来是微调阶段。在这个阶段,我们借助标注数据,调整模型以适应一个判别任务。
无监督预训练:给定一个无监督的 token 语料库$U = {u_1, . . . , u_n}$,我们使用标准的语言建模目标来最大化以下似然:
其中 k 是上下文窗口的大小,条件概率 P 使用具有参数$\Theta$的神经网络进行建模。这些参数使用随机梯度下降[51]进行训练。
在我们的实验中,我们使用多层 Transformer decoder [34]作为语言模型,这是 Transformer[62]的一个变种。该模型在输入上下文 token 上应用多头自注意力操作,然后通过逐位置前馈层来产生目标 token 上的输出分布:
其中$U = (u_{−k}, . . . , u_{−1})$是 token 的上下文向量,n 是层数,$W_e$是 token 嵌入矩阵,$W_p$是位置嵌入矩阵。l 是神经网络的层数。
在使用等式 1 中的目标训练模型之后,我们将参数调整以适应有监督目标任务。我们假设一个带标签的数据集$C$,其中每个实例包括一系列输入 token $x^1, . . . , x^m$,以及一个标签 y。该输入数据传输通过我们的预训练模型,以获得最终的 Transformer block 的激活器$h^m_l$ ,然后将其输入到新添加的线性输出层(参数为$W_y$)中以预测 y:
这给我们提供了最大化的目标:
我们还发现,在微调过程中将语言建模作为辅助目标有助于学习,原因是:(a)改善监督模型的泛化能力;(b)加速收敛。这与之前的工作[50, 43]一致,他们也观察到了使用这样一个辅助目标可以提高性能。具体来说,我们优化以下目标(权重λ):
总的来说,在微调过程中,我们仅需要额外的参数$W_y$以及分隔符 token 的嵌入(在第 3.3 节中描述)。
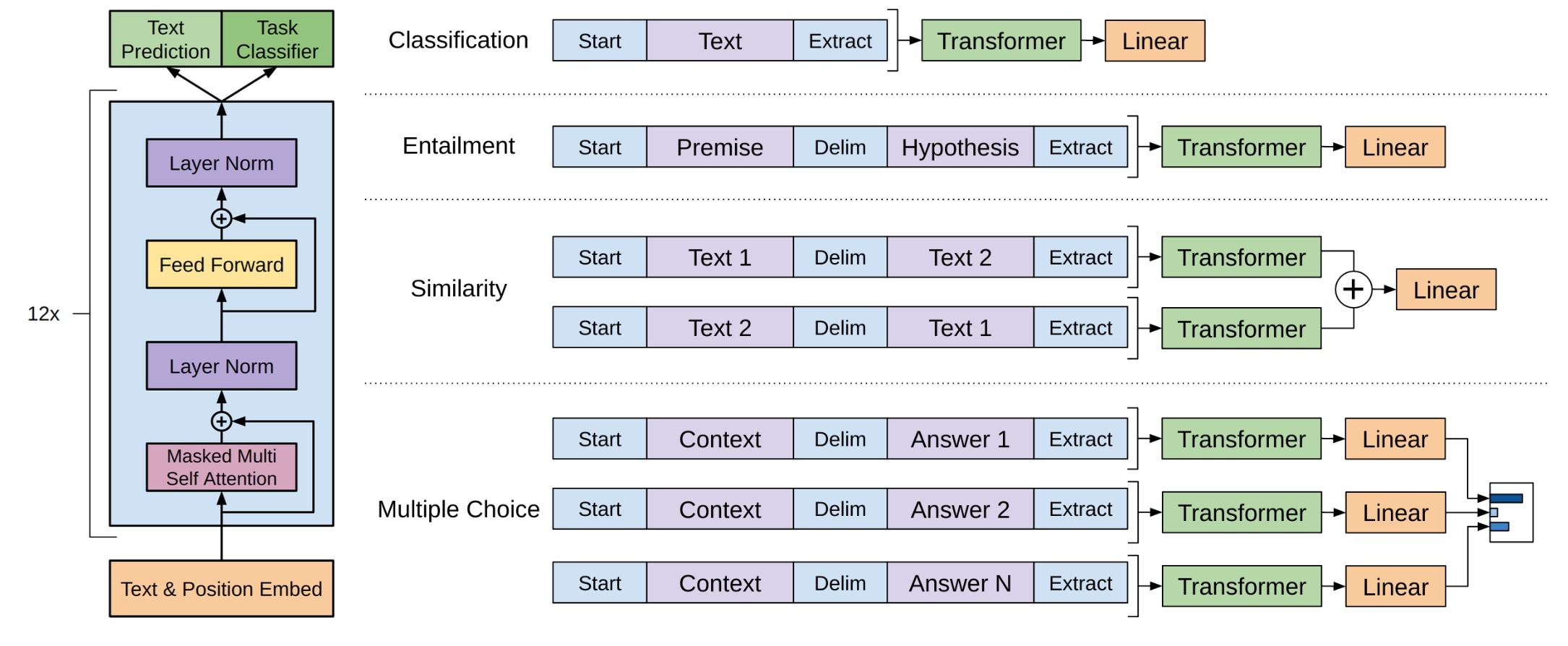
对于某些任务,如文本分类,我们可以直接按照上述方法微调我们的模型。某些其他任务,如问题回答或文本蕴含,具有结构化输入,如有序句子对或文档、问题和答案的三元组。由于我们的预训练模型是在连续文本序列上进行训练的,因此我们需要对其进行一些修改才能将其应用于这些任务。之前的工作提出了在转移表示之上学习特定任务的架构[44]。这种方法重新引入了大量任务特定的定制,并且没有为这些额外的架构组件使用迁移学习。相反,我们使用遍历式方法[52],将结构化输入转换为我们的预训练模型可以处理的有序序列。这些输入转换使我们能够避免在任务之间对架构进行大量更改。我们在下面简要描述了这些输入转换,图 1 提供了一个视觉示例。所有转换都包括添加随机初始化的开始和结束标记(⟨s⟩, ⟨e⟩)。
文本蕴含:对于蕴含任务,我们将前提 p 和假设 h 的令牌序列连接在一起,中间用分隔符标记 ($) 隔开。
相似性:对于相似性任务,比较的两个句子之间没有固有的顺序。为了反映这一点,我们修改输入序列以包含两种可能的句子顺序(中间有分隔符),并分别处理它们以生成两个序列表示 $h^m_l$,这些表示在输入到线性输出层之前按元素相加。
问题回答和常识推理:对于这些任务,我们给定一个上下文文档 z,一个问题 q 和一组可能的答案${a_k}$。我们将文档上下文和问题与每个可能的答案连接在一起,在中间添加一个分隔符标记,得到$[z;q;$;a_k]$。使用我们的模型独立处理这些序列,然后通过 softmax 层进行归一化,以生成可能答案的分布。
4. 试验
4.1 设置
无监督预训练:我们使用 BooksCorpus 数据集[71]来训练语言模型。该数据集包含超过 7,000 本不同的未发表书籍,涵盖了冒险、奇幻和浪漫等多种类型。关键在于,它包含了长篇连续的文本,这使得生成模型能够学会根据长距离的上下文信息进行条件化建模。另一个可替代的数据集是 1B Word Benchmark,它被类似的方法 ELMo[44]所使用,虽然数据集规模大致相同,但在句子层面进行了打乱处理,从而破坏了长距离的结构。在这个语料库上,我们的语言模型取得了非常低的 token 级别困惑度,达到了 18.4。
| Task | Datasets |
|---|---|
| Natural language inference | SNLI [5], MultiNLI [66], Question NLI [64], RTE [4], SciTail [25] |
| Question Answering | RACE [30], Story Cloze [40] |
| Sentence similarity | MSR Paraphrase Corpus [14], Quora Question Pairs [9], STS Benchmark [6] |
| Classification | Stanford Sentiment Treebank-2 [54], CoLA [65] |
表 1: 本次试验中用到的任务和数据集
模型规格:我们的模型主要依据原始 Transformer 架构[62]。我们训练了一个 12 层的 decoder-only Transformer,具有遮蔽式自注意力机制(768 维状态和 12 个注意力头)。对于逐位置前馈网络,我们使用了 3072 维的内部状态。我们使用了 Adam 优化方案[27],最大学习率为 2.5e-4。学习率在前 2000 次更新中从零线性增加,然后使用余弦调度退火至 0。我们在 64 个随机抽样的连续序列(每个序列包含 512 个标记)上进行 100 个周期的小批量训练。由于 LayerNorm[2]在整个模型中被广泛使用,简单的权重初始化 N(0,0.02) 就足够了。我们使用了包含 40,000 次合并[53]的字节对编码(BPE)词汇表,以及具有 0.1 正则化率的残差、嵌入和注意力 dropout。我们还采用了[37]中提出的一种修改版的 L2 正则化,对所有非偏置或增益权重 w=0.01。对于激活函数,我们使用高斯误差线性单元(GELU)[18]。我们使用学习位置嵌入替代了原始工作中提出的正弦版本。我们使用 ftfy 库来清理 BooksCorpus 中的原始文本,标准化一些标点符号和空白,并使用 spaCy 分词器。
微调细节:除非特别指定,我们会沿用无监督预训练的超参数设置。我们在分类器中添加 0.1 的 dropout 率。对于大多数任务,我们采用 6.25e-5 的学习率和 32 的批次大小。我们的模型能够快速进行微调,在大多数情况下,训练 3 个周期就足够了。我们采用线性学习率衰减调度策略,训练的前 0.2% 阶段进行预热。λ设置为 0.5。
4.2 有监督微调
我们在多种有监督任务上进行实验,包括自然语言推理、问答、语义相似度和文本分类。其中一些任务包含在近期发布的 GLUE 多任务基准测试[64]中,我们也对其进行了使用。图 1 对所有任务和数据集进行了概述。
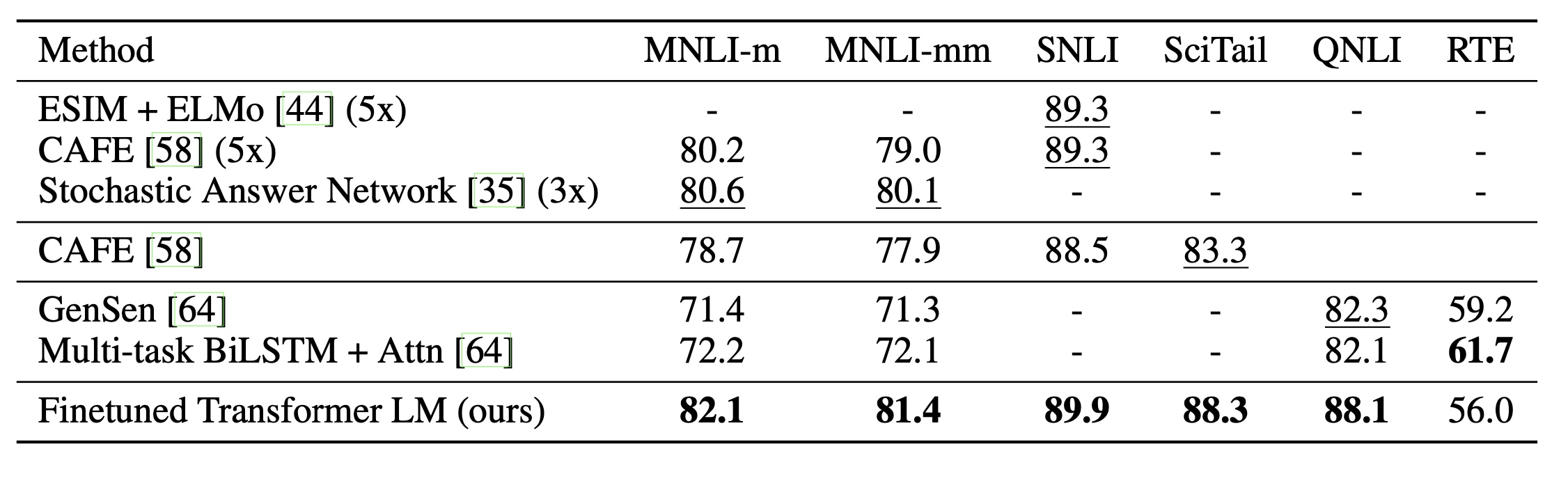
自然语言推理(NLI)任务,也称为识别文本蕴涵,涉及阅读一对句子并从蕴涵、矛盾或中立关系中判断它们之间的关系。尽管最近已经引起了很多关注[58, 35, 44],但由于存在多种现象,如词汇蕴涵、共指、词汇和句法歧义等,这个任务仍然具有挑战性。我们在五个数据集上进行评估,这些数据集来源丰富,包括图像标题(SNLI)、转录语音、通俗小说和政府报告(MNLI)、维基百科文章(QNLI)、科学考试(SciTail)或新闻文章(RTE)。
表 2 详细展示了我们的模型在不同 NLI 任务中与之前最先进方法的各种对比结果。在五个数据集中的四个上,我们的方法明显优于基准线,相较于之前的最佳结果,在 MNLI 上绝对提升达到 1.5%,在 SciTail 上绝对提升达到 5%,在 QNLI 上绝对提升达到 5.8%,在 SNLI 上绝对提升达到 0.6%。这证明了我们的模型在处理多句子推理和应对语言歧义方面的优势。在 RTE(一个较小的数据集,包含 2490 个示例)上,我们取得了 56% 的准确率,低于多任务双向 LSTM 模型报告的 61.7%。鉴于我们的方法在更大的 NLI 数据集上的强大性能,很可能我们的模型也将从多任务训练中受益,但我们目前尚未探讨这一点。
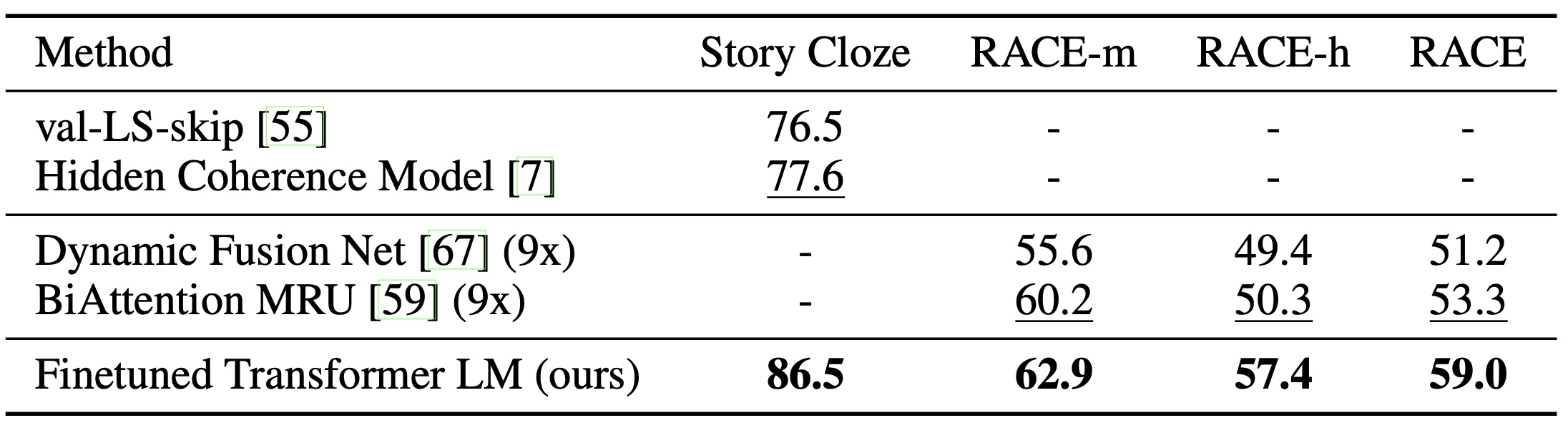
问题回答和常识推理:另一个涉及单句和多句推理的任务是问答。我们采用了最近发布的 RACE 数据集[30],该数据集包含了来自初中和高中考试的英文段落及相关问题。与 CNN [19] 或 SQuaD [47]等其他数据集相比,这个语料库包含了更多的推理类型问题,为我们的模型提供了极佳的评估,因为我们的模型经过训练能够处理长距离的上下文。此外,我们还评估了 Story Cloze Test[40],这个测试要求从两个选项中为多句故事选择正确的结尾。在这些任务上,我们的模型再次明显优于先前的最佳结果——在 Story Cloze 上最高提高了 8.9%,在 RACE 上整体提高了 5.7%。这证明了我们的模型在有效处理长距离上下文方面具有很强的能力。
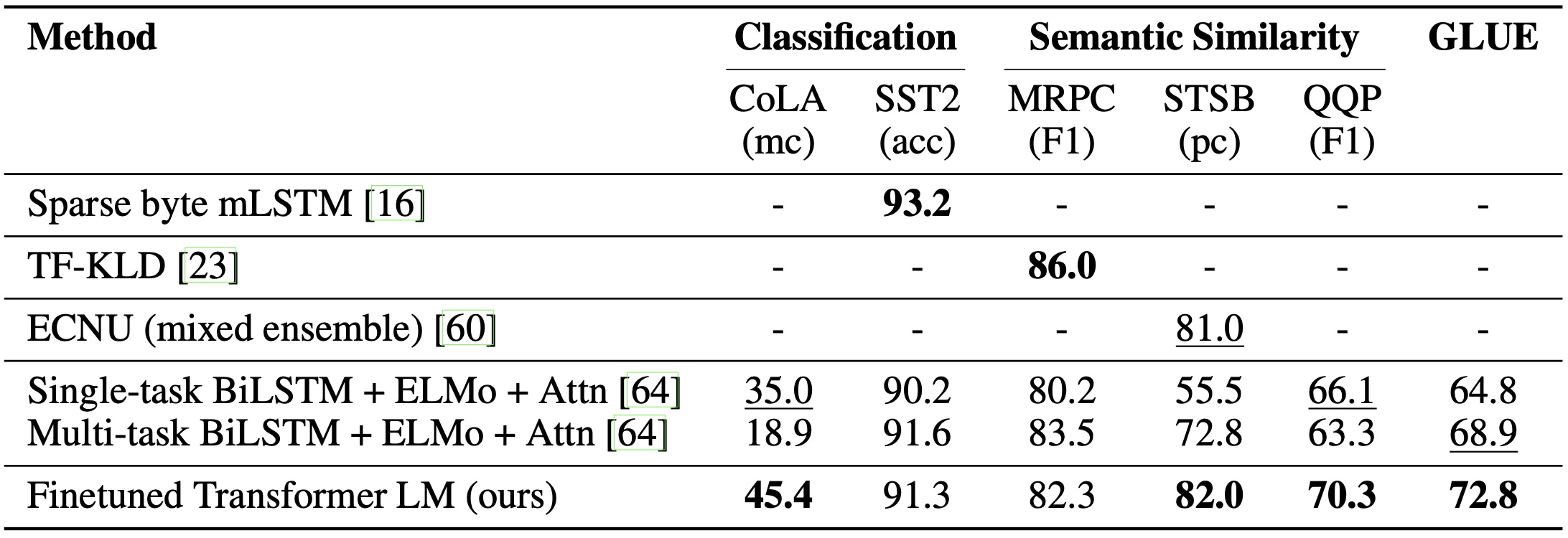
语义相似度:语义相似度(或释义检测)任务包括预测两个句子在语义上是否等价。挑战在于识别概念的重新表述,理解否定语句以及处理句法歧义。我们在这个任务中使用了三个数据集——Microsoft Paraphrase 语料库(MRPC)[14](来源于新闻报道),Quora 问题对(QQP)数据集[9],以及语义文本相似度基准(STS-B)[6]。我们在三个语义相似度任务的两个任务中取得了最佳成绩(表 4),在 STS-B 上的绝对增益达到 1 分。在 QQP 上的性能差距显著,与单任务 BiLSTM + ELMo + Attn 相比,绝对提高了 4.2%。
最后,我们在两个不同的文本分类任务上进行评估。语言可接受性语料库(CoLA)[65] 包含了关于句子是否符合语法规则的专家评判,用以测试训练模型的固有语言偏差。另一方面,斯坦福情感树库(SST-2)[54] 是一个标准的二分类任务。我们的模型在 CoLA 上获得了 45.4 分,这比先前最好的结果 35.0 有显著提高,展示了我们模型所学到的固有语言偏差。在 SST-2 上,模型也取得了 91.3% 的准确率,与最佳结果相当。我们在 GLUE 基准测试上也获得了 72.8 的总分,明显优于先前最好的 68.9。
总体来说,我们的方法在 12 个评估数据集中的 9 个上取得了新的最佳成绩,很多情况下超过了集成模型。我们的结果还表明,我们的方法在不同规模的数据集上都表现良好,从较小的数据集如 STS-B(约 5.7k 训练样本)到最大的数据集 SNLI(约 550k 训练样本)。
5. 分析
迁移层数的影响:我们观察了从无监督预训练向有监督目标任务迁移不同数量层数的影响。图 2(左)描绘了我们在 MultiNLI 和 RACE 上的方法性能,作为迁移层数量的函数。我们观察到标准结果,即迁移嵌入可以提高性能,每个 Transformer 层都能进一步带来好处,对于 MultiNLI 的完全转移,可以提高 9%。这表明预训练模型中的每一层都包含解决目标任务的有用功能。

零样本表现:我们希望更好地了解为什么对 Transformer 进行语言模型预训练是有效的。一个假设是底层生成模型为了提高其语言建模能力,学会了我们用于评估的许多任务,而 Transformer 相比 LSTM 的更结构化的注意力记忆有助于更好地迁移。我们设计了一系列启发式解决方案,使用底层生成模型在无监督微调的情况下执行任务。我们在图 2(右)中显示了在生成预训练过程中这些启发式解决方案的有效性。我们观察到这些启发式方法的性能在训练过程中稳定且稳步提高,表明生成预训练支持学习各种与任务相关的功能。我们还观察到 LSTM 在零样本性能方面波动较大,表明 Transformer 架构的归纳偏差有助于迁移。
对于 CoLA(语言可接受性),将示例按照生成模型分配的平均 token 对数概率进行评分,并通过阈值进行预测。对于 SST-2(情感分析),我们将 very 这个 token 添加到每个示例后面,并将语言模型的输出分布仅限于单词 positive 和 negative,认定被分配到的更高概率的 token 作为预测结果。对于 RACE(问答),我们选择在给定文档和问题的条件下,生成模型分配的具有最高平均 token 对数概率的答案。对于 DPRD [46](Winograd 模式),我们用两个可能的指代物替换定指代词(确定的指代词),并预测生成模型在替换后的序列其余部分分配较高平均 token 对数概率的解析。
| Method | Avg. Score | CoLA (mc) | SST2(acc) | MRPC(F1) | STSB(pc) | QQP(F1) | MNLI(acc) | QNLI(acc) | RTE(acc) |
|---|---|---|---|---|---|---|---|---|---|
| Transformer w/ aux LM (full) | 74.7 | 45.4 | 91.3 | 82.3 | 82.0 | 70.3 | 81.8 | 88.1 | 56.0 |
| Transformer w/o pre-training | 59.9 | 18.9 | 84.0 | 79.4 | 30.9 | 65.5 | 75.7 | 71.2 | 53.8 |
| Transformer w/o aux LM | 75.0 | 47.9 | 92.0 | 84.9 | 83.2 | 69.8 | 81.1 | 86.9 | 54.4 |
| LSTM w/ aux LM | 69.1 | 30.3 | 90.5 | 83.2 | 71.8 | 68.1 | 73.7 | 81.1 | 54.6 |
消融研究:我们进行了三种不同的消融研究(表 5)。首先,我们在微调过程中检查没有辅助 LM 目标的方法性能。我们观察到,辅助目标在 NLI 任务和 QQP 上有所帮助。总体趋势表明,较大的数据集从辅助目标中受益,而较小的数据集则没有。其次,我们通过将 Transformer 与使用相同框架的单层 2048 单元 LSTM 进行比较,分析了 Transformer 的效果。我们观察到,在使用 LSTM 代替 Transformer 时,平均分数下降了 5.6 分。LSTM 仅在一个数据集上胜过 Transformer —— MRPC。最后,我们还将直接在监督目标任务上训练的 Transformer 架构与没有预训练的情况进行比较。我们观察到,缺乏预训练会影响所有任务的性能,与我们的完整模型相比,下降了 14.8%。
6. 结论
我们提出了一个框架,通过生成式预训练和判别式微调,让单一的任务无关模型具备强大的自然语言理解能力。通过在包含长篇连续文本的多样化语料库上进行预训练,我们的模型学会了丰富的世界知识和处理长距离依赖关系的能力。然后,将这些知识和能力成功地应用于解决判别性任务,例如问答、语义相似度评估、蕴含关系判断和文本分类,从而在我们研究的 12 个数据集中,提高了其中 9 个的最高技术水平。在机器学习研究中,利用无监督(预)训练来提高判别任务性能一直是一个重要的目标。我们的工作表明,确实可以实现显著的性能提升,并为哪些模型(如 Transformer)和数据集(具有长距离依赖关系的文本)最适合这种方法提供了参考。我们希望这将有助于推动新的无监督学习研究,无论是在自然语言理解还是其他领域,进一步提高我们对无监督学习如何以及何时发挥作用的理解。
-
在自然语言处理(NLP)中,text representations(文本表示)是将文本转换为计算机可以处理的形式的过程。文本表示是 NLP 中的一个重要问题,因为计算机无法直接处理自然语言。因此,研究人员需要将文本转换为计算机可以理解的形式,以便进行下一步的处理,如分类、聚类、信息检索等。文本表示的目标是将文本转换为向量或矩阵的形式,使得计算机可以对其进行数学运算和统计分析。常用的文本表示方法包括以下几种:1) One-hot representation(独热表示):将每个单词表示为一个向量,其中只有一个元素是 1,其余元素均为 0。该方法不考虑单词之间的语义和上下文信息,因此效果有限。2) Bag-of-words representation(词袋表示):将文本表示为一个单词的集合,并统计每个单词出现的次数。该方法考虑了单词的出现频率,但忽略了单词之间的顺序和语义信息。3) Word embedding(词嵌入):将每个单词表示为一个低维向量,使得单词之间的距离反映了它们之间的语义关系。Word embedding 通常使用神经网络模型进行训练,例如 Word2Vec 和 GloVe 等。4) Transformer-based representation(基于 Transformer 的表示):最近的文本表示方法中,基于 Transformer 的表示方法已经成为主流。Transformer 是一种使用自注意力机制的神经网络,可以将文本转换为一系列向量,每个向量代表一个单词或短语的语义信息。BERT、GPT 等是基于 Transformer 的表示方法的代表。 ↩
-
fine-tune 翻译成微调;adaption 翻译成调整,有些翻译成适应性、适应,个人感觉在这里是调整的意思。后文也提到了,对于特定的任务,会把输入的词句做一些简单的调整(比如添加分隔符等)。 ↩
-
在机器学习中,discriminatively trained model(判别式训练模型)是一种常见的模型训练方法。该方法的主要目标是学习一个函数,该函数可以将输入数据映射到其相应的输出。与生成式模型不同,判别式模型不是直接建模联合分布 P(X,Y),而是直接建模条件分布 $P(Y X)$,也就是在给定输入 X 的情况下预测输出 Y。判别式模型通常使用梯度下降等优化方法进行训练,优化目标是最大化对数据集的条件对数似然估计,或最小化分类误差等评价指标。在训练过程中,模型根据输入数据和其正确的标签来调整模型的权重和偏差,以便更准确地预测输出。相对于生成式模型,判别式模型在许多实际应用中具有更好的性能,特别是在分类、标注、聚类等任务中。因为判别式模型直接建模了输入和输出之间的映射关系,可以更好地适应不同的输入分布和输出分布。判别式模型还具有更快的训练速度和更高的泛化能力,这使得它们成为机器学习领域的重要工具之一。需要注意的是,判别式模型的性能取决于训练数据的质量和多样性,以及模型的选择和参数调整。因此,在应用判别式模型时,需要仔细选择训练数据和模型参数,以获得最佳的性能。